Elden Ring Geoguesser
Elden Ring's world is distinct in a way most games aren't. Each area has such a strong identity that most players can immediately tell if they're in Caelid with its rot-red sky or the foggy Lakes of Liurnia. A model that takes a screenshot as input and outputs coordinates, could that work too?

Gathering Data
First, lots of data.
One option would be to automatically take screenshots (good) and label them by hand (bad). Labeling by hand is tedious and scales terribly. Since we're in a game world, it should be possible to extract that information from the game itself. Enter Cheat Engine, a program that reads data directly from memory. It's often used for cheating, but here it's a great tool to read Elden Ring's memory and pull out the coordinates we need. To find the right memory addresses we use the Elden Ring Cheat Engine table maintained by The Grand Archives.
Some Lua scripting later and we have a tool that extracts player coordinates every second.
IDS = {
anim = 100970, -- Current Animation
played = 100971, -- Length played [seconds]
cx = 107824, -- Camera X
cy = 107825, -- Camera Y
cz = 107826, -- Camera Z
map = 107917, -- Map ID (hex)
px_l = 107924, -- Local X
pz_l = 107925, -- Local Z
py_l = 107926, -- Local Y
px_g = 107928, -- Semi-Global X
pz_g = 107929, -- Semi-Global Z
py_g = 107930, -- Semi-Global Y
}
local function getVal(id) -- Function to extract data
local rec = AddressList.getMemoryRecordByID(id)
if rec == nil then return nil end
return rec.Value
end
looping, parsing and saving...
Combined with a simple Python screenshotting tool we get:
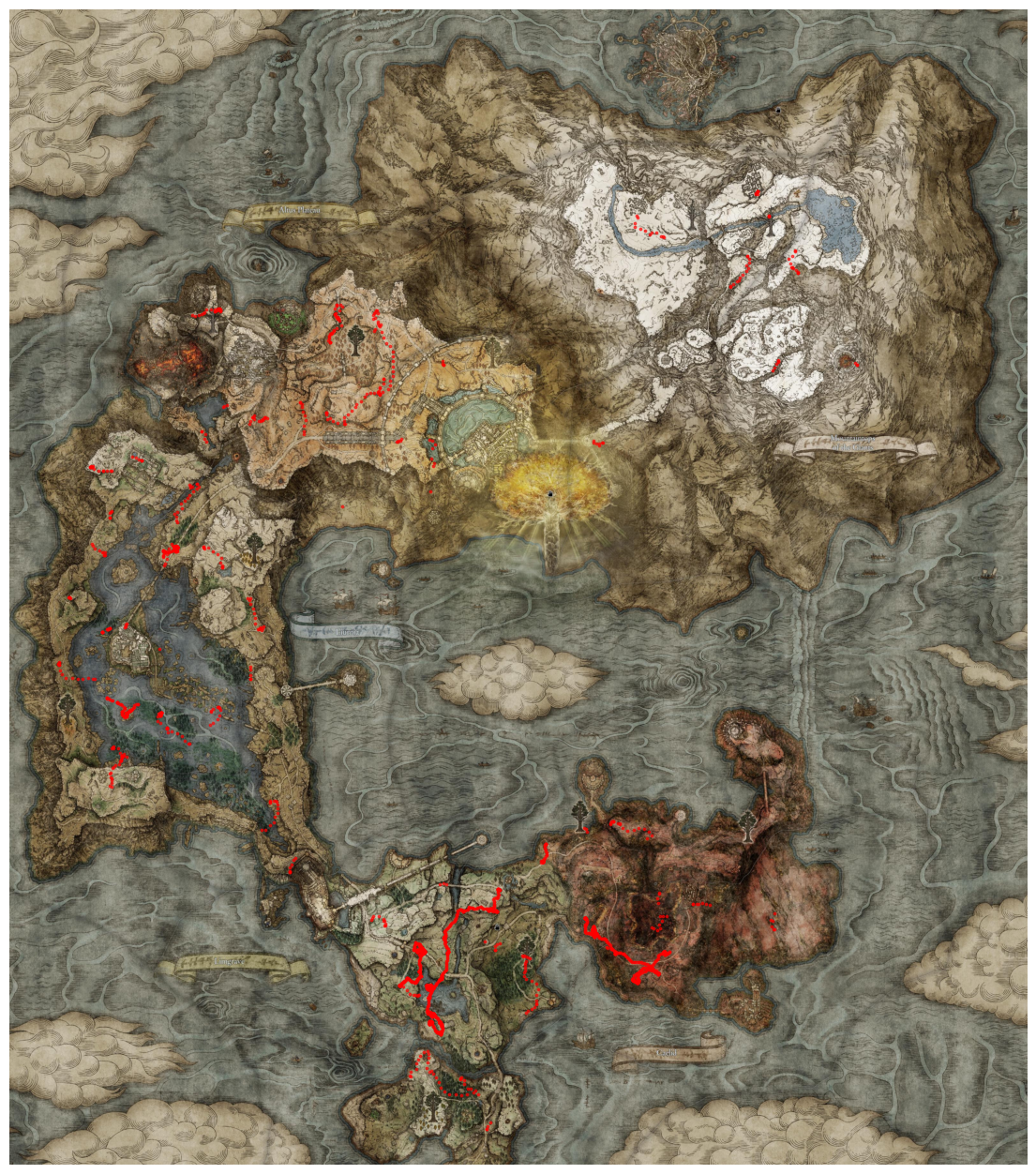
More data would be better, but it's enough for a decent prototype. On to modelling.
(There's also a bunch of coordinate math involved to convert local chunk coordinates into global ones. Check out this image by FloorBelow and soulsmodding.wikidot.com for details.)
Building a Baseline Model
The model we use is DINOv2, a vision model trained to produce useful image representations without needing labeled data. Rather than training it to classify images, we let it memorize a set of screenshots by converting them into embeddings, compact numerical descriptions of what's in each image. When we show it an unknown screenshot, it finds the most similar ones from its memory and returns their coordinates as a guess.
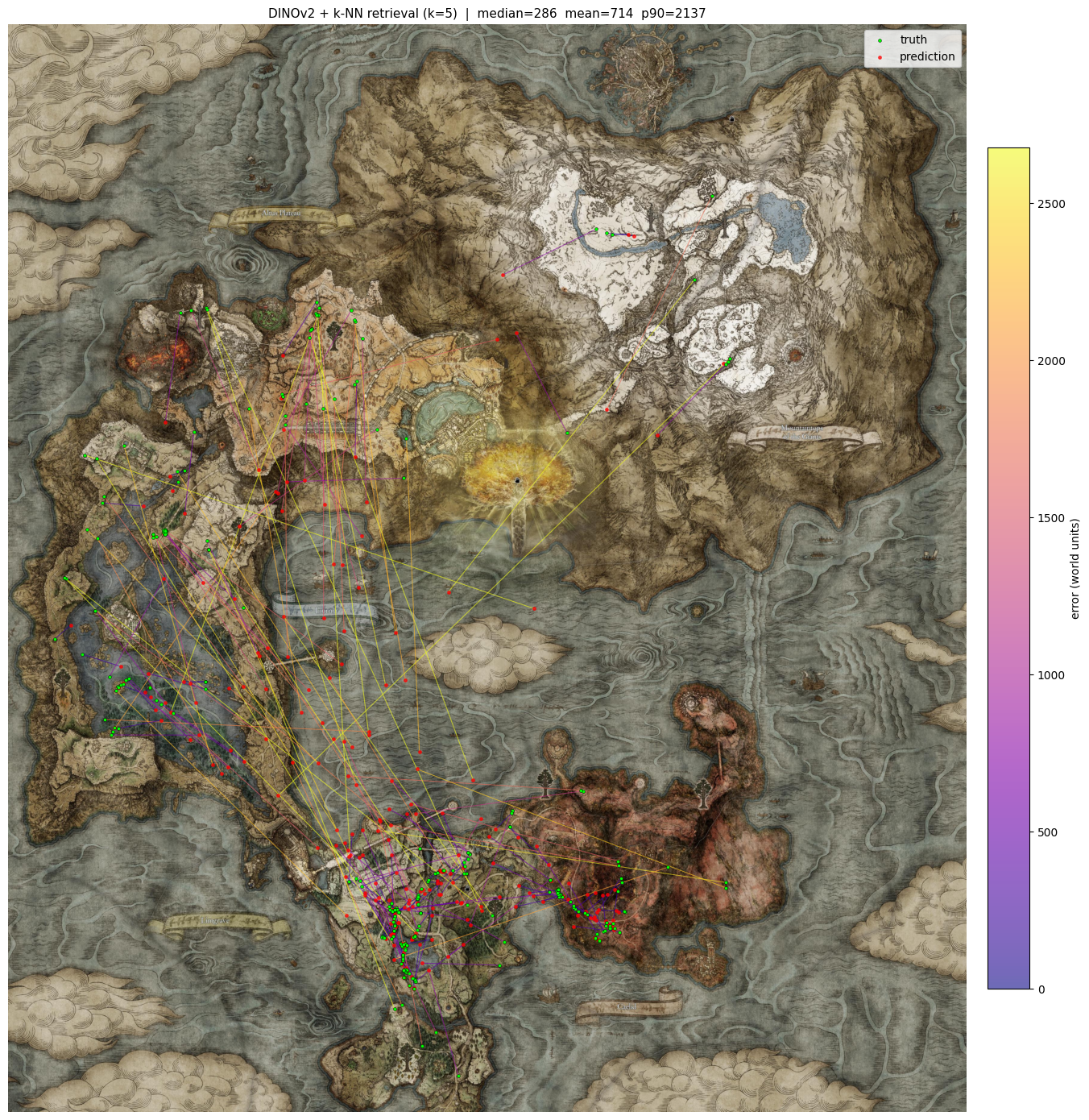
Not so promising. The input screenshot is on the left, the 5 most similar matches on the right.



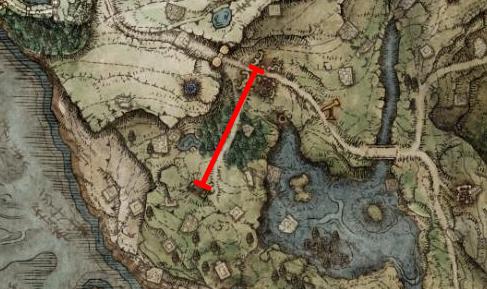
The median error is 309 world units, roughly the distance from the Church of Elleh to the Gatefront Ruins. The mean at 687 is basically twice that.
It kind of works, but has two main problems. If an image from the north and one from the south both look similar, the model averages them and lands in the sea. It also focuses on the wrong things, detecting whether the player is on a horse rather than paying attention to background details. DINOv2 was trained on generic images, not Elden Ring screenshots, so this makes sense. Time to fix that.
Fine Tuning
The base DINOv2 model had no reason to care about location. It might decide two screenshots look similar because both have the player on horseback, ignoring the background entirely. Contrastive fine-tuning teaches it a simple lesson: screenshots taken nearby should feel similar, screenshots taken far apart should feel different. After enough of those comparisons, the model stops noticing the horse and starts noticing that the ruins in the background are distinctly Limgrave.
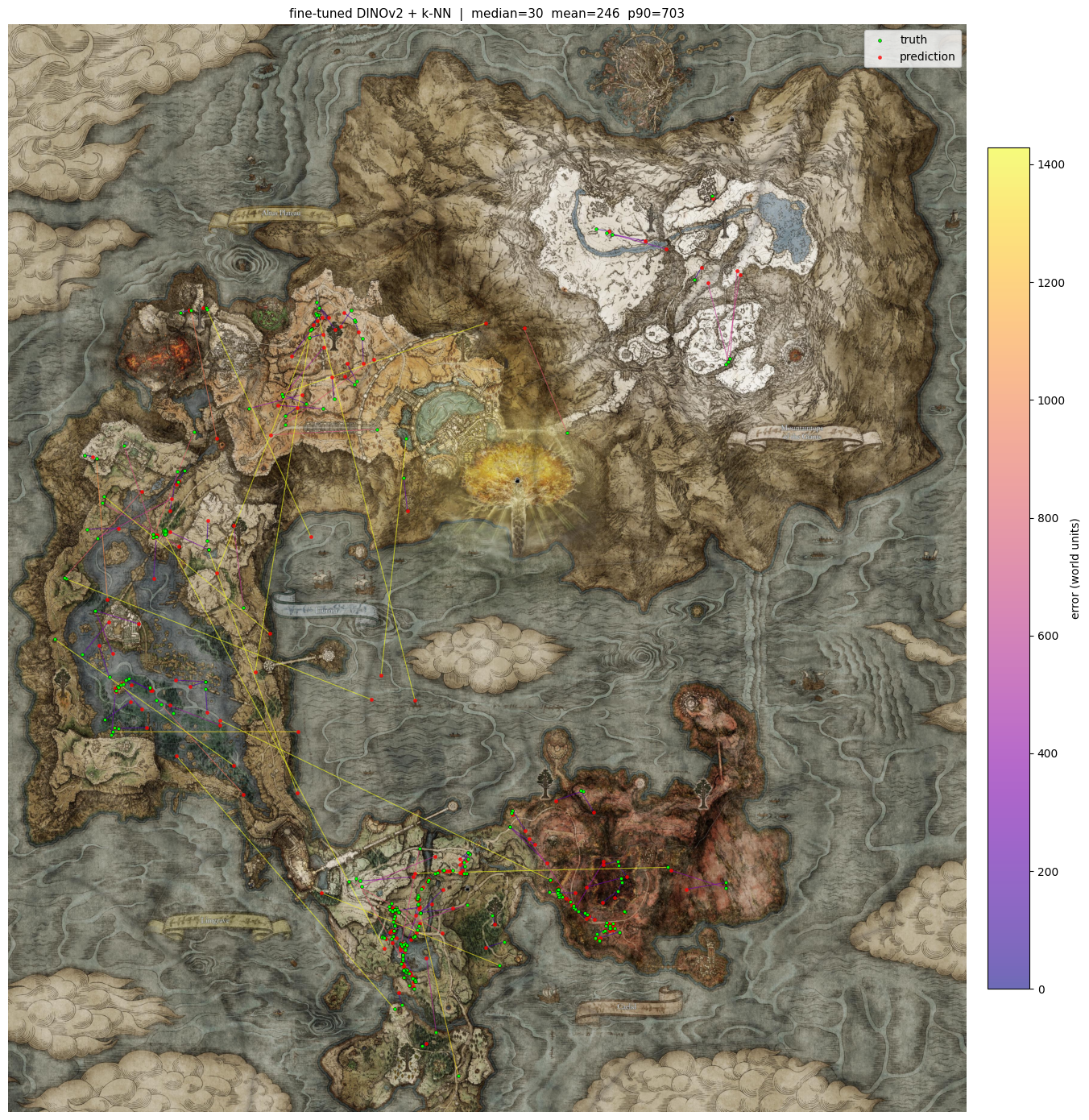
The error dropped significantly. Median went from 308.9 down to 29.5, and mean from 687.1 to 245.8. We went from a median error of "Church of Elleh to the Gatefront Ruins" to roughly a tenth of that.
Life Test
That's the next and final step..